

Configuration and Environment
Introduction
All your Supercharge configuration files are stored in the config directory. Your Supercharge application and the framework core follow these configuration files. You can adjust and tweak the app’s behavior using different values for individual options.
Using Environment Variables
Applications run in different environments using custom configurations. For example, while in local development you may use a different cache driver then in production.
Supercharge loads all environment variables configured in a .env file when starting your application. A new Supercharge application contains a .env.example file. You can copy the .env.example file and rename the copied file to .env and adjust its values.
Environment File Security
You should not commit your application’s .env file to your source control repository. Each developer in your team may require a different configuration. Also, exposing the .env file to your source control may leak sensitive credentials in case attackers gain access to the repository.
Retrieving Environment Values
All variables in your .env file are loaded into the global process.env environment object. Instead of accessing environment variables directly on process.env, you should use Supercharge’s Env facade.
The Env facade provides a convenient access the values of environment variables:
import { Env } from '@supercharge/facades'
const appName = Env.get('APP_NAME')You may also provide a default value as the second argument to the Env facade when retrieving an environment value:
const appName = Env.get('APP_NAME', 'Supercharge')Ensure Environment Values
In some situations your application won’t work when a given environment variable is not configured. The Env facade allows you to require an environment variable using the Env.getOrFail method:
import { Env } from '@supercharge/facades'
const appKey = Env.getOrFail('APP_KEY')Determine the Current Environment
You may want to determine the current application environment. The Env facade provides convenience methods to detect the current environment. It compares the NODE_ENV environment variable against a given value:
import { Env } from '@supercharge/facades'
const isProduction = Env.isProduction()
// true when NODE_ENV is set to "production"
const isNotProduction = Env.isNotProduction()
// true when NODE_ENV is not set to "production"
const isTesting = Env.isTesting()
// true when NODE_ENV is set to "test" or "testing"
const isLocal = Env.is('local')Using Configuration Values
We highly recommend putting all configuration files into the config directory because these files are automatically loaded when your application starts.
Here’s a preview how Supercharge recommends the usage of environment variables to configure your app:
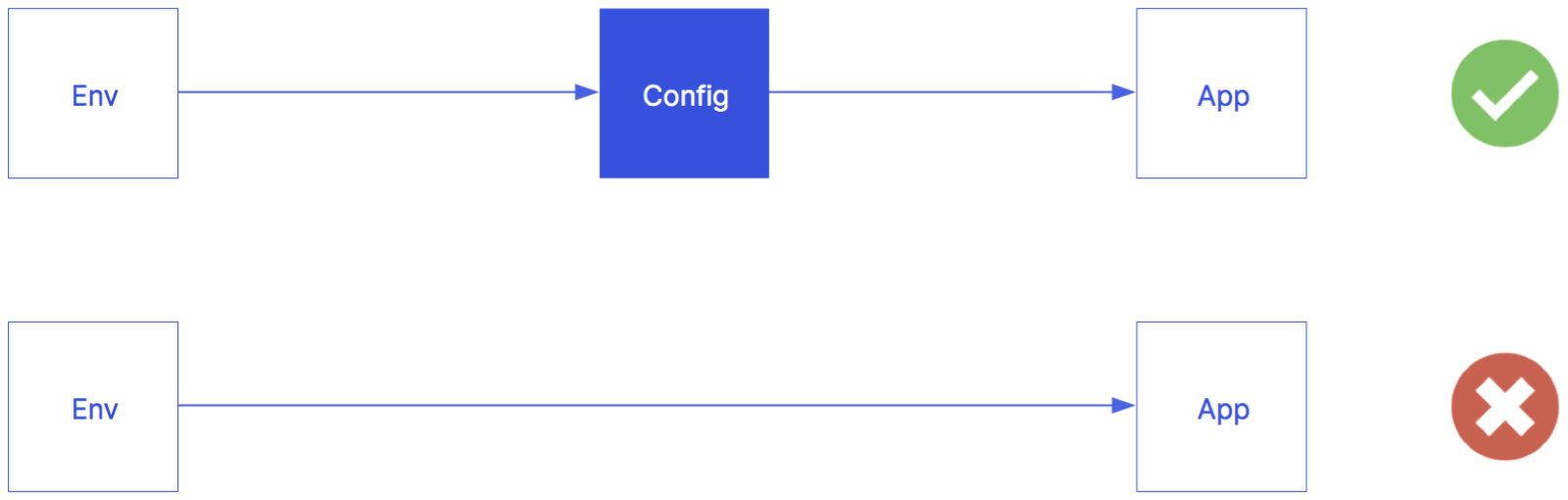
Retrieving Configuration Values
Supercharge loads all your configuration values into memory when starting the application’s HTTP server or Craft CLI. You can access the config values anywhere in your application using the Config facade or via the app instance using the app.config() method.
Use the Config.get method to retrieve configuration values. All configurations start with the configuration file name followed by a defined key. You may also retrieve nested config values using the “dot” syntax. The dot notation starts with the configuration file name followed by the nested object path:
import { Config } from '@supercharge/facades'
const appName = Config.get('app.name')You may also provide a default value as the second argument to Config.get when retrieving a config value. This default value is used when no config value exists for the provided key:
const appName = Config.get('app.name', 'My Supercharge App')Ensure Configuration Values
You may need to ensure a configuration value while building an application or community package. For example, a file cache requires a configured caching directory. In case the file cache driver doesn’t receive the configuration value for a cache directory, you may want to stop further processing.
You can require a configuration value using the Config.ensure method:
import { Config } from '@supercharge/facades'
Config.ensure('cache.file.directory')
// throws if the configuration for `cache.location` is missing